|
 |
|
|
|
|
VerfahrenEine Anwendung, die das HIT-Protokoll versteht, muss immer folgenden Ablauf berücksichtigen:
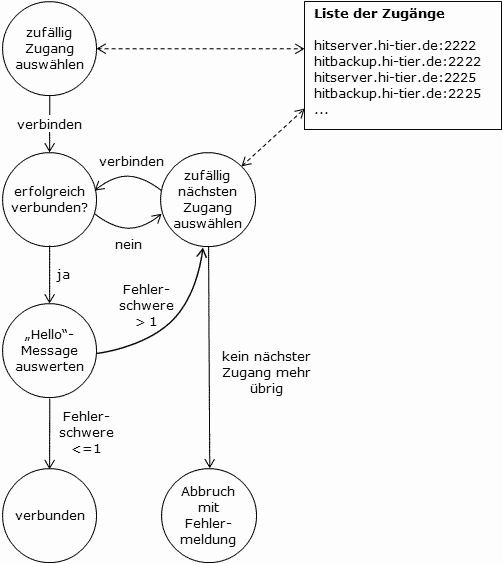
Dazu gibt es neben dem knapp beschriebenen Protokollaufbau ein paar Programmierhilfen. Seit 2004 sind speziell weitere Schritte notwendig um die HIT-Protokoll-Verschlüsselung zu implementieren. Details siehe Verschlüsselung im HIT-Protokoll Vorhandene SystemeWir betreiben verschiedene Systeme, die unterschiedliche Datenbasen haben, aber dennoch den gleichen Funktionsumfang bieten.
Alle Systeme werden sowohl für das Herkunftssicherungs- und Informationssystem für Tiere (kurz HI-Tier oder HIT) als auch für die Zentrale InVeKoS-Datenbank (kurz ZI-Daten oder ZID) verwendet. Alle Betriebe, die Tierbewegungen, Prüfberichte, Labortests, Zahlungsanspruchsübertragungen und vieles mehr melden, arbeiten mit dem Produktionssystem. Jedes Bundesland vergibt hierzu in Zentralstellen Betriebsnummern und eine dazugehörige PIN, um sich mit diesen Angaben in HIT/ZID anmelden zu können. Jemand, der sich in HIT anmelden kann, hat auch Zugang zu ZID und umgekehrt. Was der Benutzer letztendlich für Aktionen durchführen darf, liegt dann an der ihm zugeteilten Kompetenz, die in HIT und ZID größtenteils völlig unterschiedlich sind. Im Testsystem sind bereits Betriebsnummern zu verschiedenen Betriebstypen vorgegeben, um eigene Programme testen zu können. Mehr zu den Anmeldedaten im Test findet sich auf dieser Hilfeseite. Das Wartungssystem ist übergeordneten Behörden vorbehalten - daher keine Details dazu. Das Clonesystem ist eine nahezu 1:1-Kopie des Produktionssystems (maximal 1 Woche alt), bei dem anhand echter Daten getestet werden kann/darf, sofern der Benutzer die Berechtigung dazu hat. VerbindungsaufbauSämtliche oben genannten Systeme sind unter folgenden Servernamen via Socket-Verbindungen (BSD Sockets, Winsock) zu erreichen:
Die numerische Angabe sollte nicht verwendet werden, da wir uns vorbehalten, diese zu ändern! Für Zugriffe durch Firewalls siehe dort. Es gibt an allen Adressen bestimmte Port-Nummern, um auf bestimmte Systeme zugreifen zu können:
Für Meldungen bzw.
Abfragen in der ZID werden die gleichen Adressen und Ports verwendet! Anmerkung: Teilweise werden in den Beispielen auf dieser Webseite und in den von uns angebotenen Programmen wie der HitBatch-Client auch private IP-Adressen verwendet. Diese müssen ggf. auf oben genannte Adressen umgestellt werden, sonst kann keine Verbindung aufgebaut werden! VerfügbarkeitDa bei Systemwartungen oder auch bei unerwarteten technischen Problemen einzelne Ports nicht ansprechbar sein können, sollten Anwendungen dringend die Möglichkeit vorsehen, automatisch andere Adressen und Ports (siehe Tabellen oben) zu nutzen, wenn ein oder gar mehrere Zugänge eines Systems nicht erreichbar sind! Das gleiche gilt für den von uns zur Verfügung gestellten HitBatch-Client.
In seiner INI-Datei müssen die Parameter PRIMARYSERVER=hitserver.hi-tier.de PRIMARYPORT=2222 BACKUPSERVER=hitbackup.hi-tier.de BACKUPPORT=2222 Alternativ kann auch für beide Zugänge der Port Empfohlene Vorgehensweise (hier für Produktionssystem):
Das Format einer Antwort vom HIT-Server bzgl. der "Hello"-Message wird unten beschrieben. Firewalls, ProxiesAnwender, die direkt mit dem Internet verbunden sind, geben in ihrem Programm nur eine Adresse und den gewünschten Port an, um sich mit uns zu verbinden. Anwender in Firmennetzwerken o.ä., die ein lokales Netzwerk hinter einer Firewall betreiben, müssen in der Firewall mindestens zwei Ports (einen für den Test-Zugang, einen für den Produktions-Zugang) freischalten lassen! Um eine hohe Verfügbarkeit zu gewährleisten, sollten dringend zwei Ports für den Test-Zugang und zwei für den Produktions-Zugang eingerichtet werden und die eigene Anwendung wie oben im Abschnitt "Verfügbarkeit" beschrieben konfiguriert werden. Etwa so:
Im Beispiel sind die Portnummern im lokalen Netzwerk willkürlich und können vom Netzwerkadministrator vorgegeben werden. Diese Adressen und Portnummern müssen Sie dann in Ihrer Anwendung angeben. Mehr zu Proxies & Firewalls hier. Da
wir unser eigenes Protokoll für den Datenaustausch verwenden, das nicht mit
HTTP kompatibel ist, kann kein Web-Proxy verwendet werden. Neben Hardware-Firewalls in größeren LANs können Virenscanner und Software-Firewalls auf den eigenen Rechnern verhindern, dass sich Anwendungen mit den Servern verbinden können. Mehr dazu im nächsten Kapitel. SSL-Verbindungen über separate Ports bieten wir nicht an, haben aber im HIT-Protokoll eine Verschlüsselung implementiert. Mehr dazu hier. Testen einer VerbindungAuch ohne eine Anwendung läßt sich vom eigenen Rechner aus testen, ob die HitServer erreichbar sind. In einer Console (unter Windows via Eingabeaufforderung, unter Unix & Co. in einer Shell) folgendes angeben: telnet hitserver.hi-tier.de 2222 Nach dem erfolgreichen Verbindungsaufbau muss sich ein HIT-Server mit einer Hello-Nachricht melden: =0:0/116::HitServer bereit. Version NNN, TT.MM.JJJJ HH-MM. Sie sind mit dem Prod uktionssystem P1A_Quint verbunden (Server benutzt neue Betriebstabellen/NEWADS) HI-Tierzeit TT.MM.JJJJ HH-MM-SSh Challenge -8536065718885552706 oder =0:4/120:SYSTEM/*:HitServer momentan nicht verfügbar. Ist kein Verbindungsaufbau möglich oder kommt keine oder eine andere Antwort, dann sind die Verbindungsdaten zu prüfen. Eventuell muss in einer Software-Firewall eine mögliche Sperre aufgehoben bzw. auf Nachfrage eine Verbindung explizit dauerhaft zugelassen werden. Hinweis: Das Systemprogramm Kommunikation mit HIT-ProtokollGrundlegendesJede Anfrage- und Antwortzeile des HIT-Protokolls besteht immer aus
vier Komponenten, die jeweils durch ein Eine komplette Zeile wird grundsätzlich mit einem Wagenrücklauf (Carriage
Return, kurz Also: AnfragenJeder Anfrage (ob Meldung oder Abfrage) liegt eine sogenannte Entität (Name
der Datentabelle) zugrunde, auf die sie sich bezieht. Diese muss somit bei jeder Anfrage angegeben werden.
Soll beispielsweise eine Geburt gemeldet werden, dann muss die Entität Jede Anfrage erwartet zudem Spaltennamen, die dem Server entweder anzeigen,
welcher Wert in welcher Spalte gespeichert werden soll, oder aus welchen Spalten
bei Abfragen Daten geliefert werden sollen. Beide Angaben (Entität und
Spaltennamen) werden in Jede Anfrage erfordert zudem eine Aktion, was auf die Entität angewandt werden soll. Neben Abfragen gibt es mehrere Arten von Meldungsaktionen:
Es gibt keine Aktion zum Löschen von Datensätzen! Es ist somit immer nachvollziehbar, was früher mal gemeldet wurde, auch wenn es aus heutiger Sicht falsch ist (und storniert wurde). Neben der Aktion wird auch angegeben, ob die Anfrage feldweise (Code Die Aktion wird in Die Bei Meldungen werden neben den Spalten (Teil von Mehrere Subcodes, Spalten, Daten und Bedingungsketten werden jeweils durch
ein Semikolon Zusammengefasst:
AntwortenAntworten auf Anfragen bestehen pro Anfrage aus 1..n Antwortzeilen. Jede Antwortzeile liefert in Im Gegensatz zu Anfragen enthält
Zusammengefaßt:
Man muss alle Antwortzeilen einer Anfrage auswerten und dessen maximale Fehlerschwere ermitteln. Ist diese größer 1, dann müssen die Fehlermeldungen dazu ausgewertet und darauf reagiert werden! Man darf sich nie darauf verlassen, dass alle Meldungen und Abfragen fehlerfrei abgesetzt werden können! Das schließt die "Hello"-Message nach dem Connect und die Anmeldung mit ein! Tiefergehende Details rund um's HIT-Protokoll finden sich hier.
Dazu gehören feldweise und blockweise Anfragen, Aufbau von Bedingungen
für Abfragen, sogenannte Abfragefunktionen
(die mit Anmeldung und AbmeldungUm Datenänderungen oder Abfragen durchführen zu können, muss man sich erst
im System anmelden. Dazu wird die Entität *1:XS:LOGON/BNR15;PIN;MELD_WG:01 234 567 8901;123456;4 Ist in der darauffolgenden Antwort eine Fehlerschwere größer 1 vorhanden, dann ist die Anmeldung fehlgeschlagen. Eine erfolgreiche Anmeldung sieht so aus: =1:0/223:LOGON/*:"Anmeldung erfolgreich." Jetzt kann man im Rahmen der der Betriebsnummer zugeteilten Kompetenzen wie oben beschrieben Aktionen durchführen. Abmelden funktioniert analog: *9:XS:LOGOFF: (Die Angabe von Feldnamen und Datenspalten entfällt hier, daher endet die
Anfrage mit dem dritten Nach der Abmeldung bleibt die Socket-Verbindung bestehen. Man kann sich daher unter einer anderen Betriebsnummer anmelden, ohne eine neue Verbindung aufbauen zu müssen. Wird keine weitere Anmeldung benötigt, sollte die Socket-Verbindung einfach geschlossen werden. ProgrammierhilfenAllgemeinesZeichencodierungHIT/ZID arbeitet standardmässig mit dem Zeichensatz (Charset) Da im HIT-Protokoll bestimmte Zeichen nicht als Daten verwendet werden dürfen, schreibt man sich erst zwei Funktionen, die Text als Hex-Quoted und umgekehrt umsetzen. Also z.B. aus einem 20%iger NR-Anteil des ZA vorhanden; wird eingezogen wird hex-quoted 20%25iger NR-Anteil des ZA vorhanden%3B wird eingezogen und umgekehrt wieder 20%iger NR-Anteil des ZA vorhanden; wird eingezogen Das Codieren könnte recht einfach so durchgeführt werden: function textInHexQuoted(text) {
text = replace(text,"%","%25") // muss als erstes ersetzt werden!
text = replace(text,":","%3A")
text = replace(text,";","%3B")
// weitere Sonderzeichen wie Zeilenumbrüche, Tabulatoren etc
// sollten auch ersetzt werden!
return text
}
Decodieren ist da etwas schwieriger, da strenggenommen jede 2-stellige Hexadezimalzahl hinter dem % vorkommen kann. Viele Programmiersprachen bieten aber Methoden zum Übersetzen solcher Hex-Strings in Zahlen und weiter in Zeichen. Unterscheidung zwischen "nicht vorhanden" und "leer"In HIT/ZID gibt es viele Datenspalten, die keinen Wert enthalten, weil sie optional sind. Zusätzlich gibt es Zeichenkettenfelder, z.B. für Bemerkungen bei Prüfberichten, die leer sein dürfen. Um nun eine leere Zeichenkette von
einem nicht vorhandenen Wert unterscheiden zu können, wurde ein eigener Code
eingeführt: Ein *1:XS:GEBURT/...;TIERNAME;LOM:...;;DE 01 234 56789 schreibt eine leere Zeichenkette in das Feld *1:XS:GEBURT/...;TIERNAME;LOM:...;%--;DE 01 234 56789 nichts in das Feld schreibt (für die, die SQL kennen: es wird Mehr Details dazu hier. AnfragenEine Anfrage erwartet -wie oben beschrieben- vier Teile: eine Aktion, eine Entität, dazugehörige Spalten und dessen Daten bzw. bei Abfragen eine passende Bedingung. Das naheliegendste ist daher, eine Funktion zu schreiben, die diese vier Teile als Parameter übernimmt und daraus eine vollwertige HITP-Anfrage bastelt. Etwa so (schematisch): function baueAnfrage(aktion,entity,spalten,datenOderBedingung) {
return "*2:"+aktion+":"+entity+"/"+spalten+":"+datenOderBedingung
}
Da man technisch betrachtet zwischen Meldungen und Abfragen unterscheidet, kann man sich auch statt dessen zwei Funktionen schreiben. Für Meldungen kann dann ein Hash mit Schlüssel-Wert-Paaren (auch Dictionary, Map oder assoziatives Array genannt) verwendet werden, um sicherzustellen, dass die gleiche Anzahl Spalten wie Daten angegeben wird. Etwa so: function baueMeldung(aktion,entity,hash) {
if aktion beginnt mit "R" then Fehlermeldung "Funktion baueAbfrage verwenden!"
keys = leeres Array
values = leeres Array
for each eintrag in hash
key aus eintrag holen
key in hex-quoted umwandeln
key an Array "keys" anhängen
value aus eintrag holen
value in hex-quoted umwandeln
value an Array "values" anhängen
next
alle Elemente von "keys" mit ";" verknüpfen
alle Elemente von "values" mit ";" verknüpfen
return "*2:"+aktion+":"+entity+"/"+keys+":"+values
}
Für Abfragen dann etwa dies: function baueAbfrage(aktion,entity,spalten,bedingung) {
if aktion beginnt nicht mit "R" then Fehlermeldung "Funktion baueMeldung verwenden!"
return "*2:"+aktion+":"+entity+"/"+spalten+":"+bedingung
}
Die laufende Nummer bei jeder Anfrage kann man automatisch hochzählen, muss man aber nicht. Sie kann wie im Beispiel statisch bleiben. Hat man sich asymmetrisch verschlüsselt an HIT angemeldet, muss die Zeile als Ganzes symmetrisch verschlüsselt werden, siehe Verschlüsselung. Die Zeichenkette,
die eine der Funktionen liefert, wird schließlich um den Zeilenumbruch AntwortenWie oben unter Grundlegendes bereits erwähnt, muss man zu einer Anfrage (egal ob Meldung oder Abfrage) immer alle Antworten lesen. Dies gilt auch für die "Hello"-Message direkt nach einem Verbindungsaufbau! Eine Leseroutine sollte daher vereinfacht folgendes tun: function leseVonHit() {
antworten = leeres Array
Schleife:
Lese Zeile vom Socket
Entferne ggf. CRLF am Ende
if Zeile beginnt mit "#" then Zeile symmetrisch entschlüsseln
Zeile in Array "antworten" merken
if Zeile beginnt mit "=" then Schleife abbrechen
Wiederhole Schleife
return antworten
}
Die grün markierte Zeile ist notwendig, wenn man sich mit einem Sitzungsschlüssel (und weiteren notwendigen Spalten) asymmetrisch verschlüsselt an HIT angemeldet hat, siehe Verschlüsselung. Das erhaltene Array der Antworten muss dann unbedingt ausgewertet werden. Da jedes Element dieses Arrays eine nahezu einheitliche Form besitzt, bietet es sich an, eine Funktion zu schreiben, die jede Antwortzeile in ihre Bestandteile zerlegt. Idealerweise legt man sich dazu auch eine Struktur, ein Objekt oder ein Hash für Schlüssel-Wert-Paaren (auch Dictionary, Map oder assoziatives Array genannt) an, in dem eine ganze Antwortzeile abgebildet wird. Hier exemplarisch als Struktur: structure Antwort {
antwortnummer // Integer
unternummer // Integer oder leer
schwere // Integer
antwortcode // Integer
meldung // String (=Entität)
feldliste // Array aus Strings oder leer
datenliste // Array aus Strings oder leer
}
Eine Antwortzeile wird dann gemäß der obigen Formatbeschreibung einer Antwort etwa wie folgt in seine Bestandteile zerlegt: function zerlegeAntwort(zeile) {
antwort = neue Struktur o.ä. anlegen
Zerlege zeile in maximal 4 Komponenten anhand ":"
Extrahiere antwortnummer und ggf. unternummer aus komponente1
Beide Teile als antwortnummer und unternummer in "antwort" speichern
Zerlege komponente2 in maximal 2 Teile anhand "/"
Beide Teile als schwere und antwortcode in "antwort" speichern
Zerlege komponente3 in maximal 2 Teile anhand "/"
Teil1 als meldung in "antwort" speichern
if Teil2 ist nicht leer then
Zerlege Teil2 anhand ";" in einzelne Spalten
Spalten als feldliste in "antwort" speichern
end if
Zerlege komponente4 anhand ";" in einzelne Daten
Schleife über alle Daten
Datenspalte aus hex-quoted in Text umwandeln
Entferne rechts und links die beiden Hochkommas, wenn vorhanden
Wiederhole Schleife
Daten als datenliste in "antwort" speichern
return antwort
}
Wichtig: Die beschriebene Struktur Das Lesen der Antworten von HIT und Zerlegen dieser kann natürlich auf einmal geschehen. Dazu einfach oben in der Leseroutine das dunkelrot markierte durch folgendes ersetzen: antwort = zerlegeAntwort(Zeile)
antwort in Array "antworten" merken
Hat man alle erhaltenen Antworten zu einer Anfrage gelesen und zerlegt, muss die maximale Schwere aller Antworten ermittelt werden. Etwa so: function liefereSchwere(antworten) {
maximaleSchwere = -999
Schleife über alle antworten
if schwere aus antwort > maximaleSchwere then
maximaleSchwere = schwere aus antwort
end if
Wiederhole Schleife
return maximaleSchwere
}
Je nach maximaler Schwere muss reagiert werden:
Um bei einer Datenabfrage (Aktion datenzeilen = leeres Array
Schleife über alle antworten
if Antwort mit Schwere >= 0 then Wiederhole Schleife
if Array "datenzeilen" ist leer then
kopfzeile = feldliste
end if
datenliste aus "antwort" an Array "datenzeilen" anhängen
Wiederhole Schleife
Bei Abfragen werden Kopfzeilen im HIT-Protokoll nur bei der ersten Antwort
ausgeben und bei den nachfolgenden zur Abfrage gehörenden Antworten
weggelassen, um die Datenübertragung zu beschleunigen. Daher wird im Codestück
die Weitere HilfenUm Funktionalitäten der Weboberflächen nachbilden zu können, kann man sich (nach Anmeldung) den sogenannten HitCache anzeigen lassen. Dieser zeigt die beim Arbeiten in der Webanwendung bisher abgesetzten HIT-Protokoll-Anfragen an. Die Seite ist im HIT zu erreichen unter: HIT-Menü
In ZID gibt es das Pendant unter: ZID-Menü
|
|
|